1 · Introducción y problema
Una red de sensores GNSS distribuida de norte a sur de Chile, administrada por el CSN, produce series-tiempo de posicionamiento. El desplazamiento derivado de GNSS a 1 Hz no se satura en sismos de gran magnitud —a diferencia de velocidad y aceleración—, pero su señal arrastra un ruido de ~3–7 cm (media 4 cm) por efectos no corregidos: ionósfera, troposfera y fase de la onda satélite–receptor.
El valor estimado se hace significativo desde ~5 cm de desplazamiento —equivalente a un sismo de magnitud 6,9 Mw—. De ahí la pregunta de investigación que vertebra el trabajo: ¿es posible diseñar un filtro predictivo de ruido que otorgue mayor sensibilidad a la detección?
2 · Hipótesis y objetivos
Hipótesis. Es posible diseñar e implementar un filtro predictivo basado en modelos de aprendizaje profundo que reduzca el ruido en señales GNSS en tiempo real, mejorando la sensibilidad para la detección de eventos sísmicos y habilitando herramientas modulares para sismología.
Objetivo general: desarrollar e implementar un filtro de ruido eficiente para flujos GNSS en tiempo real. Objetivos específicos:
- 1Analizar exhaustivamente las secuencias de la red de estaciones GNSS para comprender sus características y patrones.
- 2Seleccionar y aplicar modelos predictivos que permitan procesar e interpretar esas secuencias.
- 3Definir métricas precisas para evaluar el rendimiento de los modelos según sus hiperparámetros.
- 4Diseñar estrategias de paralelización eficientes para implementar el filtro en GPU.
3 · Metodología y modelos
El trabajo procede en dos fases. Fase 1 — análisis estático: caracterización de tramos fijos de serie-tiempo para establecer una línea base (estructura micro y macro). Fase 2 — modelos: diseño e implementación de arquitecturas de aprendizaje profundo para filtrar ruido y predecir, agrupando por patrones individuales y grupales, evaluando además la paralelización a GPU.
Sensor-foco y grafo de vecindad
La red se modela como un grafo: cada estación es un nodo que abstrae al sensor y su información, y las aristas conectan estaciones consideradas vecinas según un criterio de distancia. Cada estación se trata así como un centro local (sensor-foco): el modelo extrae —vía convolución o LSTM— los patrones de su vecindad, ya que las estaciones cercanas exhiben tendencias asociadas cuando no hay sismo. Esta representación es la que permite generalizar tomando las estaciones como centros y descartar o ajustar las de menor compatibilidad con el resto.

Modelos comparados
CNN/MLP · modelo base (baseline)
Etapa convolucional que extrae características sobre el conjunto de estaciones cercanas y sus tres ejes (N, E, U); la convolución produce un vector de características (Z≈9796) que se concatena con vectores de tiempo, posición y distancia, y una etapa MLP fully-connected entrega la señal decodificada con ruido reducido.
RNN/LSTM · mejor modelo
Red recurrente con memoria selectiva a corto y largo plazo (LSTM). A diferencia del baseline no usa convolución: tres capas LSTM bidireccionales en cascada actúan como extractor de características, seguidas de una capa MLP fully-connected de salida. Es la que mejor gestiona las dependencias temporales (mejor AICc).
Transformer · estado del arte
Codificador–decodificador con codificación posicional (necesaria porque la auto-atención no captura el orden temporal por sí sola), capas de auto-atención (cada token influye en cualquier otro sin importar la distancia secuencial), red feed-forward puntual y auto-atención con máscara (evita la fuga de información futura, clave en predicción). Aprovecha GPU en paralelo; en este trabajo no alcanzó el desempeño esperado.
La evaluación combina dos métricas complementarias. El Error Cuadrático Medio (MSE) penaliza la diferencia punto a punto entre la predicción y el valor real:
MSE = (1⁄n) · Σi=1n ( yi − ŷi )2
La distancia DTW (Dynamic Time Warping) estima el error entre dos series-tiempo mediante un índice de similitud basado en la forma de cada curva —qué tan parecidas son—, alineándolas pese a desfases temporales. Así complementa al MSE: capta semejanzas de forma que la comparación punto a punto no ve. El trabajo advierte que DTW tiene dos desventajas importantes, por lo que se emplea junto al MSE y no en su lugar.


4 · Resultados
Los modelos RNN/LSTM fueron los más efectivos para la predicción a partir de datos históricos, superando a CNN/MLP en métricas como el AICc. El Transformer no alcanzó el desempeño esperado y requeriría ajustes de arquitectura para capturar patrones más complejos. Ambos modelos principales se adaptaron a la geografía estudiada tomando las estaciones como centros locales (Fig. 4–5).
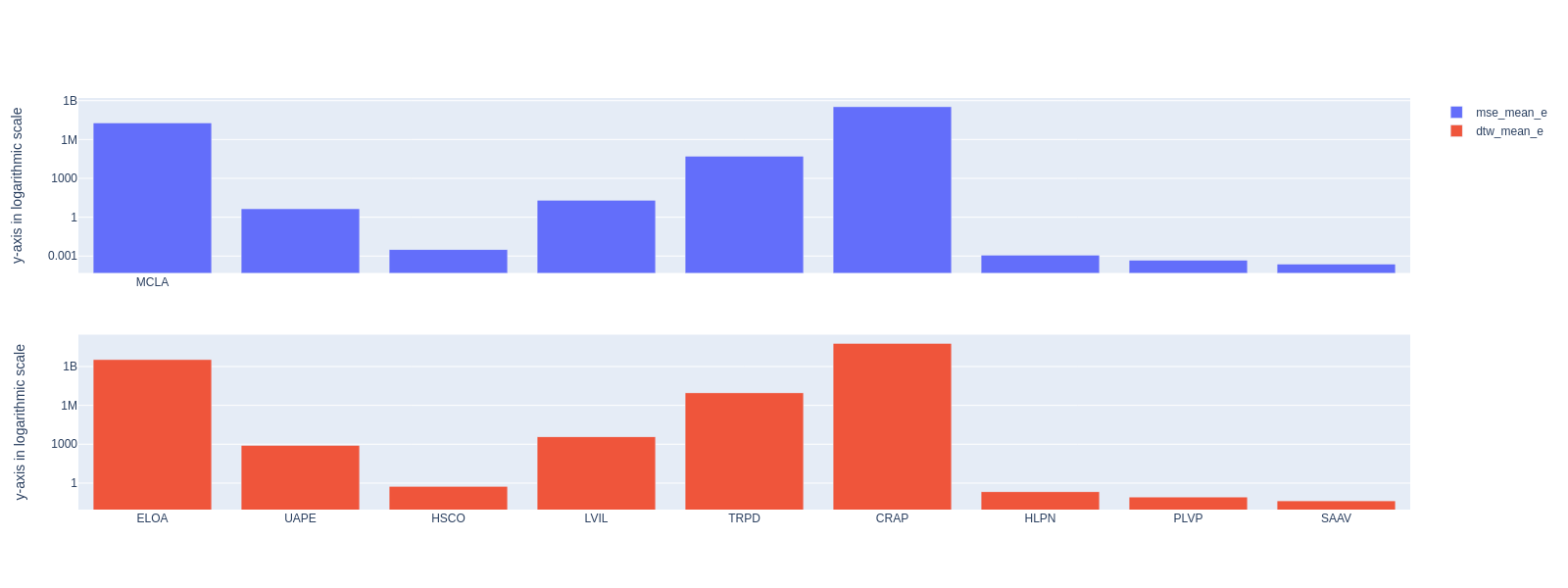
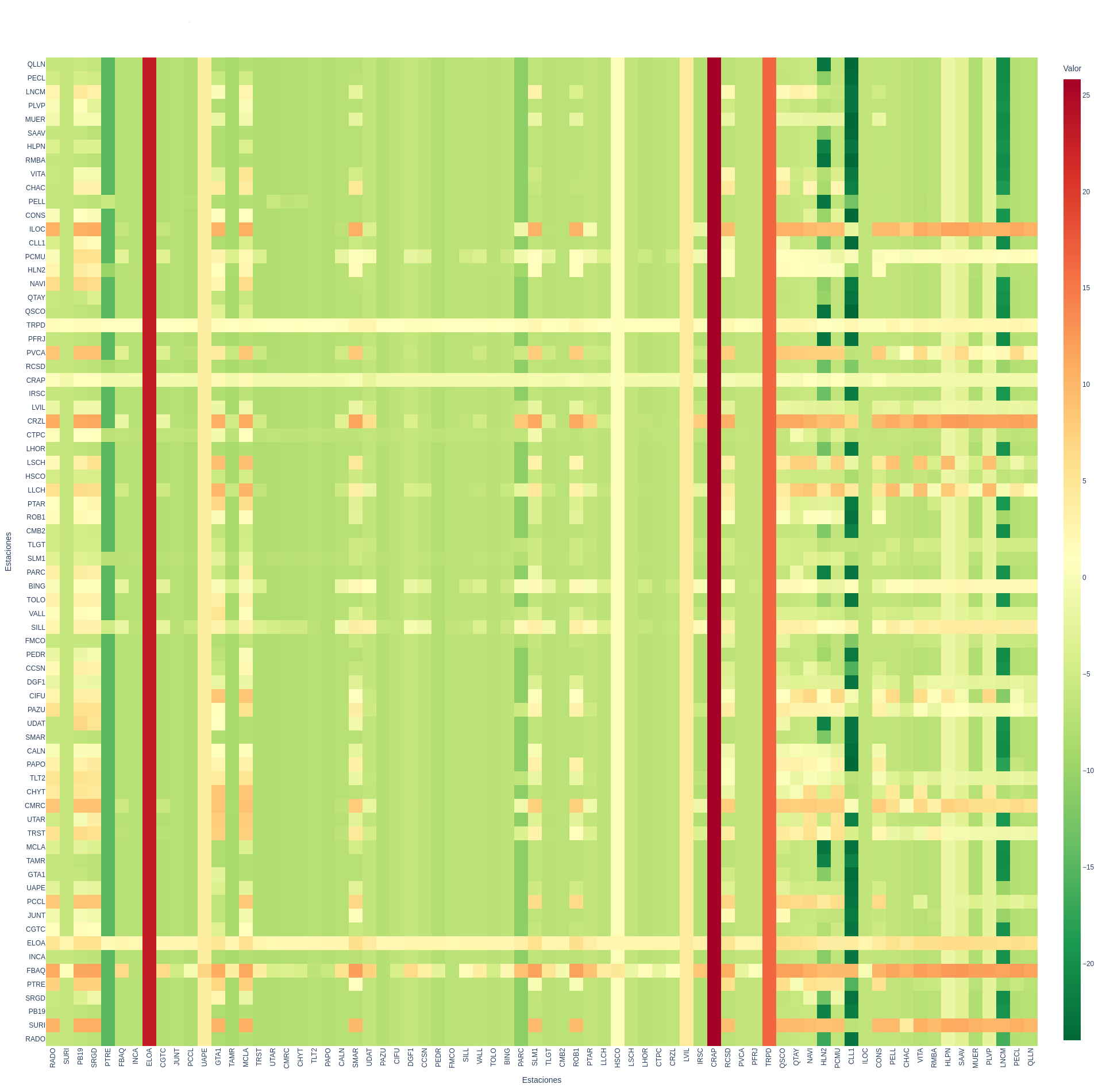
5 · Conclusiones
- Mejor modelo. RNN/LSTM: gestiona secuencias temporales, mejor ajuste a las guías de onda y contención del ruido más eficiente.
- Limitaciones. Sincronización de datos, estaciones que dejan de emitir y memoria GPU insuficiente para arquitecturas más complejas.
- Potencial de expansión. El ordenamiento desarrollado permite incorporar vectores adicionales (velocidad, aceleración) para sismos de baja intensidad.
- Impacto. Base para monitoreo sísmico en tiempo real; transferible a medición de ondas en cuerpos (electrodos) o sensores industriales.
6 · Estructura del documento
- 1Introducción — problema, hipótesis, objetivos, metodología
- 2Marco teórico — GNSS, geodesia, redes neuronales
- 3Análisis estático — caracterización de tramos fijos
- 4Diseño de modelos — CNN/MLP, RNN/LSTM, Transformer
- 5Resultados — métricas, comparación de arquitecturas
- 6Análisis dinámico — comportamiento en tiempo real
- 7Conclusiones — hallazgos, límites, trabajo futuro
Referencias
- [1] Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS. https://arxiv.org/abs/1706.03762
- [2] Sakoe, H. & Chiba, S. (1978). Dynamic programming algorithm optimization for spoken word recognition. IEEE TASSP. https://doi.org/10.1109/TASSP.1978.1163055
- [3] McInnes, L. et al. (2020). UMAP: Uniform Manifold Approximation and Projection. arXiv:1802.03426. https://arxiv.org/abs/1802.03426
- [4] Melgar, D. et al. (2018). Real-time high-rate GNSS displacements for large earthquakes. Geophys. Res. Lett. https://doi.org/10.1029/2018GL078991
- [5] Ruhl, C. J. et al. (2017). GNSS displacement sensitivity vs. seismic magnitude. Geophys. Res. Lett. https://doi.org/10.1002/2017GL075675
El documento completo incluye 50 referencias (library.bib).
Cómo citar
@mastersthesis{pineda2024gnss,
author = {David Pineda},
title = {Filtro predictivo de ruido en se\~nales GNSS
con modelos de aprendizaje profundo},
school = {Universidad de Chile, DCC},
year = {2024},
type = {Tesis de Mag\'ister en Ciencias menci\'on Computaci\'on}
}